Thuật toán indexing
Các thuật toán indexing sử dụng trong vector database đóng vai trò tạo ra một cấu trúc dữ liệu mà có thể truy vấn một cách nhanh chóng. Thường thì các thuật toán này sẽ cố gắng biến đổi các vector sang một dạng nén để tối ưu quá trình truy vấn.
Dưới đây là một vài thuật toán và cách tiếp cận của chúng trong việc xử lý vector embedding.
Random Projection (Phép chiếu ngẫu nhiên)
Ý tưởng cơ bản của thuật toán này là chiếu một vector nhiều chiều sang một không gian ít chiều hơn bằng cách sử dụng một ma trận chiếu ngẫu nhiên. Đầu tiên chúng ta sẽ tạo một ma trận với các phần tử ngẫu nhiên. Kích thước của ma trận sẽ là số chiều trong không gian mà chúng ta muốn chiếu vector tới. Sau đó chúng ta sẽ tính tích vô hướng của các vector đầu vào với ma trận, sẽ tạo ra được một ma trận chiếu (projected matrix) có chiều nhỏ hơn vector ban đầu.
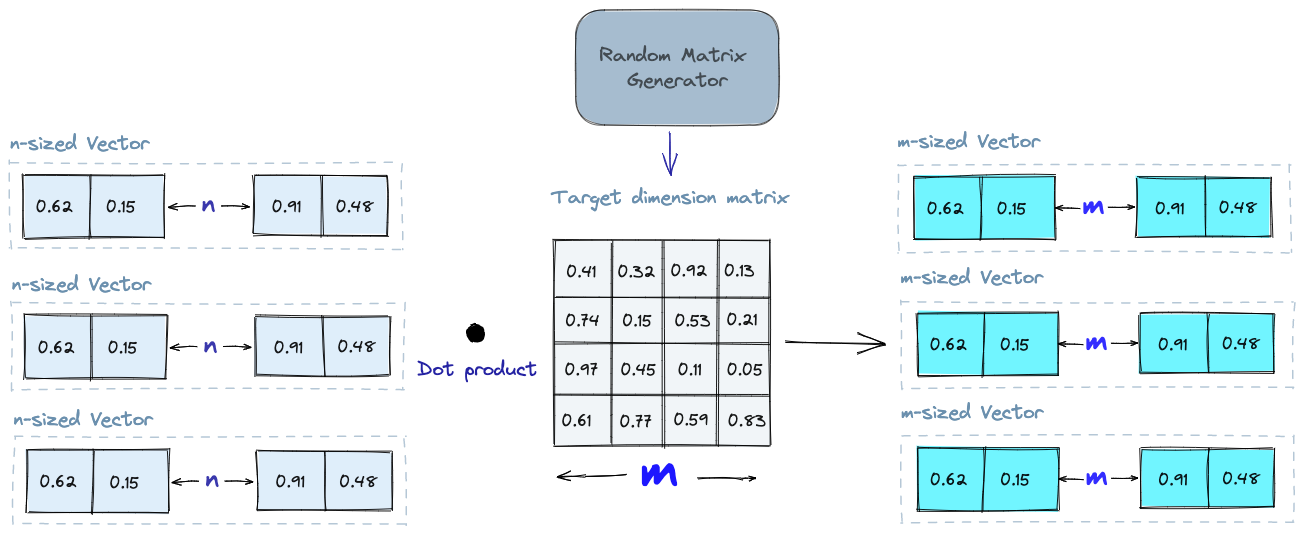
Khi truy vấn, chúng ta sẽ sử dụng ma trận chiếu vừa được khởi tạo để chiếu vector truy vấn sang một chiều không gian nhỏ hơn. Sau đó chúng ta sẽ so sánh vector chiếu vừa được tạo ra với các vector chiếu trong database, vì số lượng chiều thấp hơn nên thời gian tìm kiếm sẽ nhanh hơn nhiều so với việc tiềm kiếm trong không gian có số chiều lớn.
Cần nhớ rằng, phép chiếu ngẫu nhiên là một phương pháp xấp xỉ, chất lượng của một phép chiếu sẽ phụ thuộc vào ma trận chiếu. Thường thì ma trận chiếu càng ngẫu nhiên, thì chất lượng của phép chiếu sẽ càng tốt. Nhưng không phải dễ để tạo ra một ma trận chiếu thực sự ngẫu nhiên như vậy. Xem thêm về phép chiếu ngẫu nhiên
Product Quantization
Một cách khác để tạo thứ tự cho các vector đó là product quantization (PQ), đây là một phương pháp nén có mất mát cho các vector có số chiều lớn như là vector embedding. Đầu tiên, vector gốc sẽ được chia nhỏ ra thành nhiều phần, các phần này sẽ được đơn giản hóa bằng cách tạo ra một đoạn code đại diện cho mỗi phần, và sau đó sẽ ghép các phần này lại với nhau - tất nhiên là sẽ tránh việc mất mát thông tin, đây là điều tối quan trọng cho các phép tính so sánh độ tương đồng sau này. Quá trình thực hiện PQ có thể chia làm 4 phần: tách nhỏ, huấn luyện, mã hóa, và truy vấn
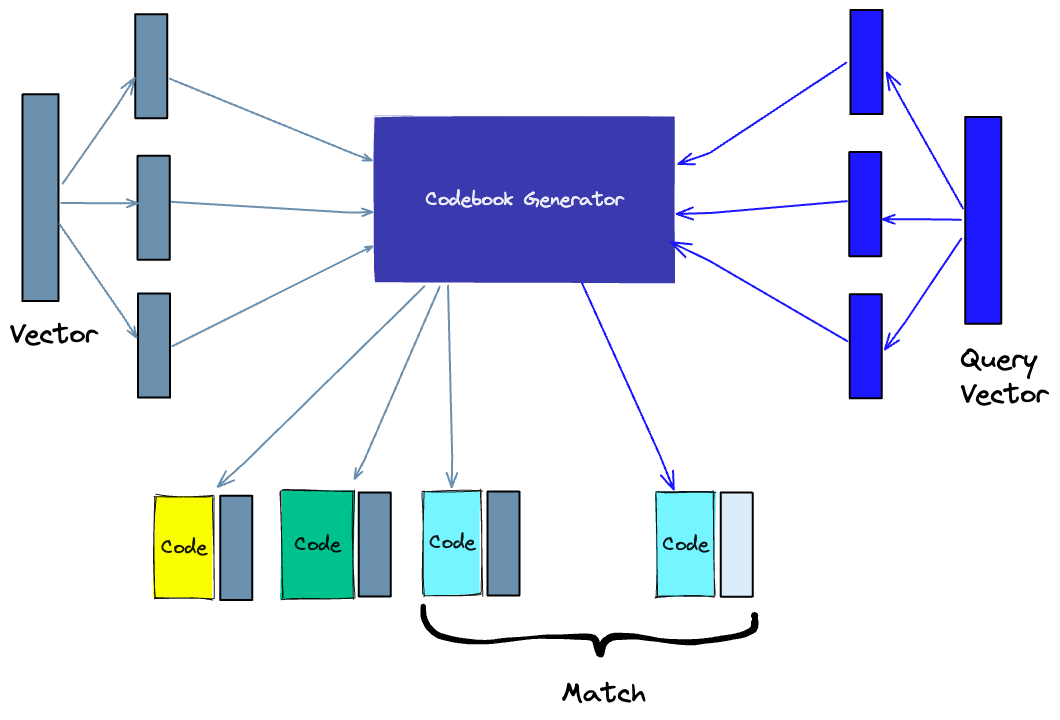
- Tách nhỏ: các vector sẽ được chia nhỏ ra thành nhiều phần
- Huấn luyện: chúng ta sẽ xây dựng một thuật toán (gọi là codebook)có thể tạo ra được các đoạn code riêng cho mỗi vector. Chúng ta sẽ thực hiện k-means trên mỗi thành phần được tách ra từ bước 1, trung tâm của các cluster sẽ trở thành codebook mà ta sẽ sử dụng. Như vậy, số lượng giá trị trong code book của mỗi thành phần sẽ bằng với giá trị k trong k-means.
- Mã hóa: Thuật toán sẽ gán một đoạn code cho mỗi phần. Trong thực tế, chúng ta sẽ tìm giá trị gần nhất trong codebook với mỗi thành phần. PQ Code cho mỗi thành phần sẽ là định danh cho giá trị tương ứng trong codebook. Chúng ta có thể sử dụng bao nhiêu PQ code tùy thích, đồng nghĩa với việc chúng ta có thể lựa chọn hàng loạt các giá trị từ codebook để thể hiện cho mỗi thành phần.
- Truy vấn: khi truy vấn, thuật toán sẽ chia nhỏ vector thành các thành phần nhỏ và sử dụng codebook để mã hóa chúng. Sau đó, dựa vào các đoạn code của các phần trong database, chúng ta sẽ tìm ra vector gần nhất với vector truy vấn.
Số lượng vector đại diện trong codebook sẽ tạo ra sự đánh đổi giữa độ chính xác của các vector đại diện so với chi phí tính toán khi tìm kiếm trong codebook. Số lượng vector đại diện trong codebook càng nhiều thì chi phí tìm kiếm càng lớn và ngược lại. Xem thêm về PQ
Locality-sensitive hashing
Locality-sentitive Hashing (LSH) biến đổi các vector tương tự nhau thành các “buckets” sử dụng một tập các hàm băm.
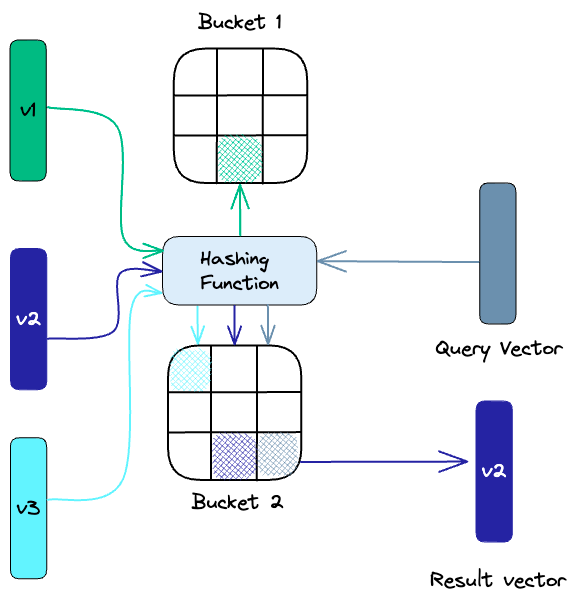
Để tim kiếm nearest neighbors (giá trị có độ tương đồng cao nhất) cho một vector truy vấn, chúng ta sẽ sử dụng các hàm băm trước đó để đưa nó vào các “buckets” có sẵn và so sánh với các vector trong bucket để tìm ra vector có độ tương đồng cao nhất. Phương pháp này giảm đáng kể thời gian tìm kiếm vì số lượng vector trong mỗi bucket ít hơn nhiều so với toàn bộ vector trong database.
Đây là một phương pháp xấp xỉ, chất lượng của nó phụ thuộc vào chất lượng của các hàm băm. Thường thì, càng nhiều hàm băm được sử dụng thì kết quả xấp xỉ sẽ càng tốt, nhưng sẽ đánh đổi bằng chi phí tính toán. Xem thêm về LSH
Hierarchical Navigable Small World (HNSW)
HNSW sẽ tạo ra một cấu trúc dạng cây với mỗi node đại diện cho một tập các vector. Nhánh giữa các node sẽ đại diện cho độ tương đồng giữa các vector. Đầu tiên, thuật toán sẽ tạo ra một tập các node, mỗi node sẽ chứa một lượng nhỏ các vector. Việc này có thể được thực hiện ngẫu nhiên hoặc phân cụm các vector sử dụng các thuật toán như k-means, mỗi cụm sẽ trở thành 1 node.
Sau đó, thuật toán sẽ phân tích các vector trong mỗi node và vẽ một nhánh nối các node có độ tương đồng với nhau cao nhất, cuối cùng sẽ tạo thành một đồ thị.
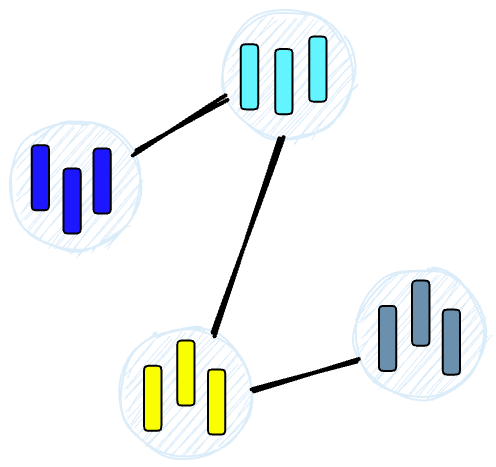
Khi chúng ta truy vấn một HNSW, nó sẽ sử dụng đồ thị này để duyệt qua cây để tìm đến node có nhiều khả năng sẽ chứa một vector có độ tương đồng cao nhất so với query vector. Xem thêm về HNSW
Chúng ta đã nhắc nhiều về việc so sánh các vector để tìm ra độ tương đồng, ta sẽ đi chi tiết về phần này trong bài tiếp theo.