Database Operations
Vector database có các chức năng phù hợp để sử dụng trong môi trường high scale production. Dưới đây là bức tranh tổng thể về các thành phần trong database
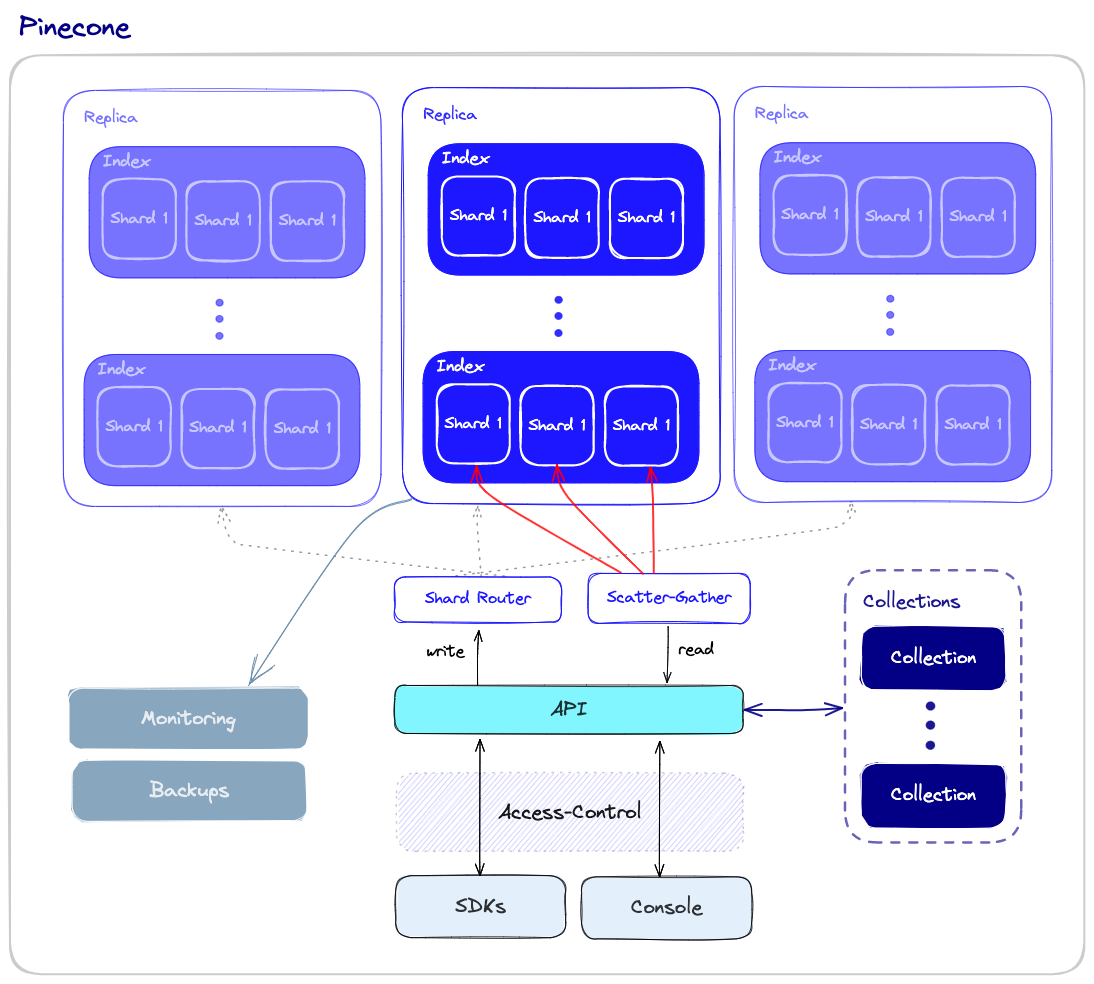
Hiệu năng và khả năng chịu lỗi (Performance and Fault tolerance)
Hiệu năng và khả năng chịu lỗi có liên quan chặt chẽ với nhau. Dữ liệu càng nhiều thì số lượng node cũng sẽ càng nhiều, và sẽ có nhiều nguy cơ phát sinh ra lỗi. Chúng ta mong muốn rằng vector query phải được thực hiện càng nhanh càng tốt cho dù có một số node bị lỗi, có thể là do lỗi ở phần cứng, lỗi mạng,.. Các loại lỗi này có thể dẫn đến thời gian chờ lâu hơn hoặc thậm chí là sai kết quả query.
Để đảm bảo chất lượng hiệu năng và khả năng chịu lỗi, vector database sử dụng data sharding (phân chia dữ liệu) và data replication (nhân rộng dữ liệu):
- Sharding - phân chia dữ liệu vào các node. Có nhiều cách để phân chia data - ví dụ như phân chia theo sự tương đồng của các cụm khác nhau của dữ liệu, sao cho các vector tương tự nhau sẽ ở trên cùng một vùng. Khi có query, nó sẽ được gửi đến tất cả các vùng và kết quả sẽ được lấy ra và kết hợp lại với nhau. Phương thức này còn được gọi là “scatter-gather” pattern.
- Replication - tạo ra nhiều bản copy của dữ liệu vào các node khác nhau. Điều này đảm bảo rằng cho dù một node nào đó xảy ra lỗi, thì sẽ có node khác thay thế nó. Cách làm này có kết quả ổn định hơn nhưng có thể gây ra độ trễ cao.
Monitoring (quan sát)
Để quản lý và duy trì vector database một cách hiệu quả, chúng ta cần một hệ thống monitoring có thể theo dỗi các thành phần quan trọng của hiệu năng database. Monitoring là thiết yếu để có thể phát hiện sớm các vấn đề, tối ưu hiệu năng, bảo đảm hệ thống hoạt động ổn định. Vài thứ quan trọng mà chúng ta nên theo dõi đó là:
- Resource usage (tài nguyên sử dụng) - ví dụ như CPU, RAM, dung lượng ổ đĩa, các giới hạn về tài nguyên có thể ảnh hưởng đến hiệu năng của database.
- Query performance (hiệu năng truy vấn) - query latency, throughput, và tỉ lệ lỗi có thể giúp phát hiện sớm các vấn đề của hệ thống cần được xử lý.
- System health - toàn bộ system health monitoring bao gồm thông tin từ các node, tiến trình replication và các thành phần quan trọng khác.
Access control (quản lý truy cập)
Access control là tiến trình quản lý và điều phối truy cập của user vào dữ liệu và tài nguyên. Đây là một thành phần quan trọng của an toàn dữ liệu, bảo đảm răng chỉ các user được cấp phép mới có thể xem, sửa hoặc tương tác với dữ liệu lưu trong vector database. Access control là quan trọng vì:
- Data protection (Bảo vệ dữ liệu): một ứng dụng AI thường sẽ có các thông tin nhạy cảm và riêng tư, một cơ chế quản lý truy cập có thể ngăn chặn các truy cập không được cấp quyền và các vi phạm.
- Compliance (tuân thủ): nhiều lĩnh vực như sức khỏe, tài chính sẽ có các quy định về tính riêng tư của dữ liệu. Một cơ chế quản lý truy cập có thể giúp tổ chức tuân theo các quy định này, bảo vệ họ khỏi vi phạm.
- Accountability and auditing (trách nhiệm và kiểm toán): Cơ chế quản lý truy cập cho phép tổ chức quản lý hoạt động của user bên trong vector database. Thông tin này cần thiết cho việc auditing, khi mà các sai phạm về bảo mật xảy ra, nó sẽ giúp truy vết lại các truy cập chưa được cấp phép hoặc chỉnh sửa.
- Scalability and flexibility (mở rộng và linh hoạt): một tổ chức sẽ mở rộng và phát triển, nhu cầu về quản lý truy cập có thể thay đổi. Một hệ thống quản lý truy cập sẽ cho phép chỉnh sửa và mở rộng các quyền của user, bảo đảm an toàn dữ liệu sẽ vẫn ổn định khi tổ chức lớn mạnh.
Backups and collections
Khi mọi thứ đều gặp lỗi, vector database cung cấp tính năng dựa vào các bảo sao lưu được tạo thường xuyên. Các bản backup này có thể được lưu trữ trên các hệ thống bên ngoài hoặc các dịch vụ đám mây, bảo đảm tính an toàn và khả năng phục hồi dữ liệu. Trong trường hợp mất mát dữ liệu, các backups này có thể được sử dụng để phục hồi database về lại trạng thái trước đó, giảm thiểu tối đa ảnh hưởng đến hệ thống chung.
API and SDKs
Lập trình viên tương tác với database sẽ muốn làm việc với một API đơn giản, quen thuộc. Vector database cung cấp giao diện thân thiện với người dùng, đơn giản hóa quá trình phát triển một ứng dụng có khả năng tìm kiếm với hiệu năng tốt.
Vector database cũng cung cấp ngôn ngữ lập trình SDKs, giúp cho các lập trình viên dễ dàng tương tác với database trong ứng dụng của họ. Điều này giúp cho lập trình viên tập trung vào nhu cầu của họ mà không phải lo lắng về các cấu trúc phức tạp bên dưới của database.
Tổng kết
Sự phát triển của vector embedding trong các lĩnh vực NLP, Computer vision và các ứng dụng AI đã tạo nên sự lớn mạnh của vector database như là một công cụ giúp chúng ta tương tác hiệu quả với vector embedding. Trong bài tiếp theo, tôi sẽ viết về Qdrant, một framework cung cấp vector database được sử dụng phổ biển trong cộng đồng.