Thực hiện tìm kiếm độ tương đồng vector có thể được thực hiện chỉ trong phần trăm giây. Ở đó, filtering là một công đoạn khó khăn nhất khi thực hiện tìm kiếm trên những tập dữ liệu khổng lồ.
Bài viết này sẽ giải thích 2 hướng tiếp cận thường thấy trong bài toán filter và những giới hạn của chúng,
Bài toán Filtering
Trong bài toán tìm kiếm vector tương tự, chúng ta sẽ tạo ra một vector đại diện cho dữ liệu (có thể là hình ảnh, văn bản, ..), lưu trữ chúng trong database, và tìm kiếm trong đó sử dụng một query vector.
Trong bài toán tìm kiếm và các hệ thống khuyến nghị gần như luôn cần đến công đoạn filtering để giới hạn số lượng tìm kiếm trong những vector có liên quan, và trong nhiều trường hợp, công đoạn này là đặc biệt cần thiết để nâng cao trải nghiệm khách hàng.
Mặc dù tính thiết yếu như vậy, vẫn chưa có các hướng giải quyết tốt cho bài toán metadata filtering - giới hạn số lượng vector tìm kiếm dựa vào metadata.
Ví dụ, chúng ta cần xây dựng một ứng dụng tìm kiếm cho một tập đoàn lớn để tìm kiếm trong toàn bộ tài liệu của họ. Người dùng thường muốn giới hạn tìm kiếm của họ chỉ ở trong một bộ phận cụ thể. Ví dụ như đoạn pseudo-code dưới dây:
top-k where department == 'engineering'
OR
top-k where department != 'hr'
top-k where {“department”: {"$eq": "engineering"}}
OR
top-k where {“department”: {"$ne": "hr"}}
và nếu chúng ta muốn chỉ tìm kiếm trong các dữ liệu ở trong các tuần gần nhất, hoặc muốn xem tài liệu đã thay đổi như nào theo thời gian - Chúng ta cần giới hạn không gian tìm kiếm chỉ đến những bản ghi cũ.
top-k where date >= 14 days ago
OR
top-k where date < 3 years ago
top-k where {“date”: {"$gte": 14}}
OR
top-k where {“date”: {"$lt": 1095}}
Và có vô vàn cách kết hợp query như sau
top-k where date >= 14 days ago AND department == 'finance'
top-k where {"date": {"$gte": 14}, “department”: {"$eq": "finance"}}
Nếu như không có công đoạn filter thì việc tìm kiếm sẽ khó khăn hơn nhiều. Như việc Excel không có data filters, SQL không có lệnh WHERE, và python không có if..else. Nhưng việc áp dụng các kỹ thuật filter vào trong việc tìm kiếm vector không hề dễ dàng.
Pre-query filtering
Phương pháp đầu tiên đó là pre-filter các vector, phương pháp này sẽ áp dụng các điều kiện lọc trước khi sử dụng ANN (Approximate nearest neighbor). Pre-query filtering sẽ áp dụng các điều kiện lọc vào các vector và sẽ trả về một danh sách kết quả - các vector có metadata thõa mãn điều kiện lặp. Sau đó, similarity search sẽ được thực hiện trên kết quả lọc này. Dưới đây là một ví dụ về việc khách hàng tìm kiếm một mẫu áo khoác jean Levi’s, thì trước tiên, tất cả các áo khoác thương hiệu Levi’s sẽ được lọc ra, và danh sách này sẽ được sử dụng để thực hiện vector similarity search.

Phương pháp này tưởng chừng như là một giải pháp hợp lý, nhưng có nhược điểm là tiến trình search sẽ chậm, bởi vì tất cả dữ liệu cần được lọc trước khi thực hiện ANNS, chi phí tính toán cho phương pháp này rất lớn.
Post-query filtering
Như tên gọi, post-query filtering sẽ sử dụng các điều kiện lọc vào kết quả mà query ra được. Ví dụ, cũng đối với bài toán tìm áo ở phần trên, thì hệ thống sẽ search ra các loại áo khoác giống nhất với trong ảnh, sau đó, kết quả sẽ được lọc ra theo nhãn hiệu của nó trong metadata.

Tuy nhiên, một nhược điểm không thể tránh khỏi của cách là này đó là số lượng kết quả có metadata thõa mãn điều là không thể dự đoán được (có thể cực kỳ lớn hoặc là quá ít so với cái ta cần). Trong trường hợp tệ nhất, sẽ không cho ra được kết quả nào khi áp dụng post-query filtering.
In-query filtering
Đây là một phương pháp ANNS và filtering được thực hiện đồng thời. Ví dụ trong mua sắm online, các hình ảnh của áo khoác jean sẽ được chuyển đổi thành các vector embedding và thông tin về thương hiệu cũng sẽ được lưu dưới dạng scalar cũng với các vector.
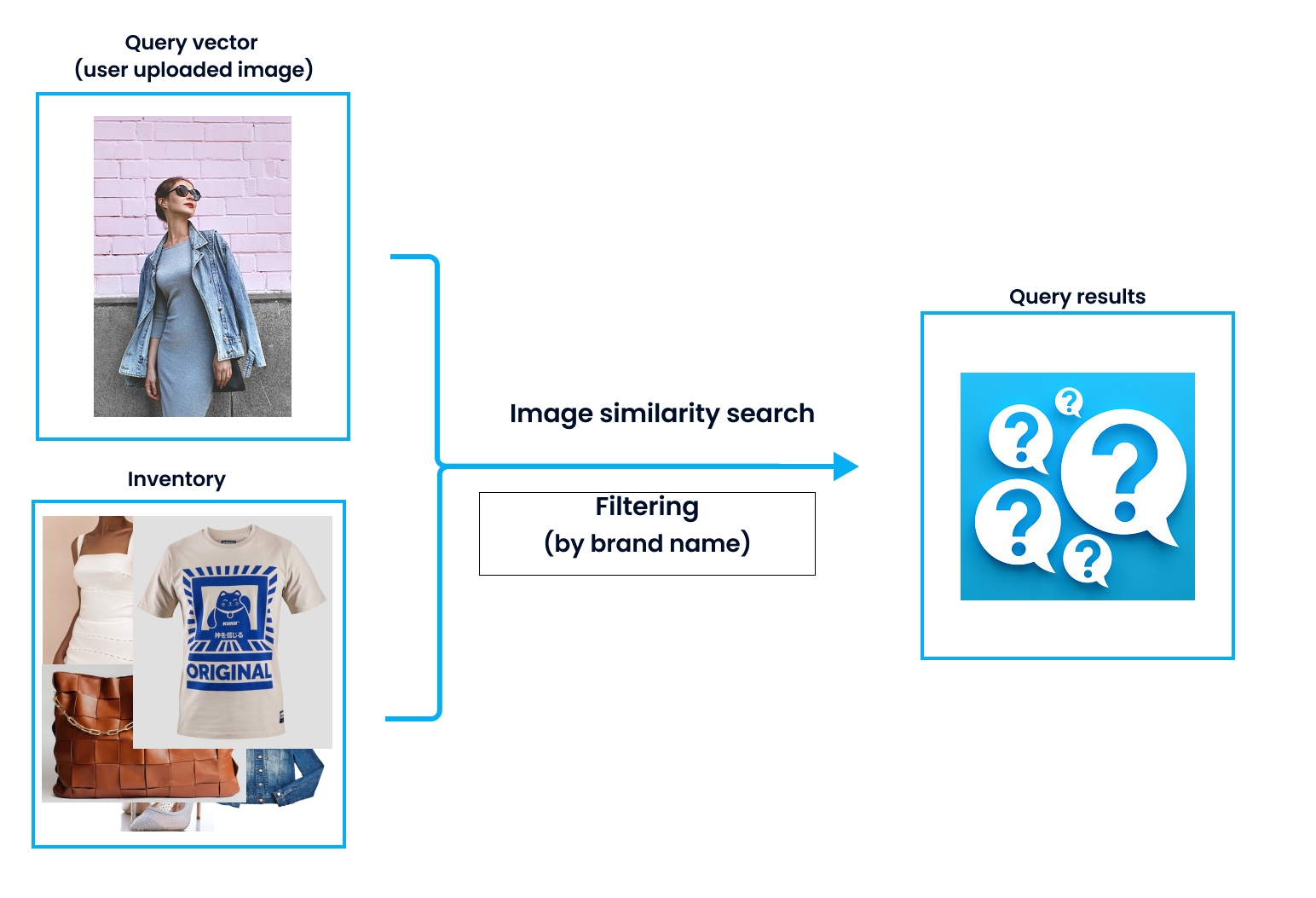
Đối với các làm này thì sẽ cần một hệ thống rất mạnh mẽ, vì sẽ cần tải lên bộ nhớ cả thông tin về vector embedding và dữ liệu về metadata cho filtering, việc search và filtering sẽ được diễn ra đồng thời. Trong trường hợp có quá nhiều thông tin cần lọc, rất có thể hệ thống sẽ xảy ra tình trường tràn bộ nhớ.
Tổng kết
Trên đây là 3 phương pháp thường thấy khi áp dụng filtering cho vector similariry search. Mỗi framework vector database khác nhau cũng sẽ có các phương pháp tiếp cận khác nhau.
Reference
- https://zilliz.com/learn/attribute-filtering
- https://www.pinecone.io/learn/vector-search-filtering/