Giới thiệu
Nhiều người mới làm về ML nghĩ rằng các mô hình ML hay neural network là toàn bộ một hệ thống ML. Tuy nhiên trong thực tế, một hệ thống ML liên quan đến nhiều thức phức tạp, bao gồm các thành phần như quản lý data, hệ thống máy chủ, evaluation pipeline để đánh giá hệ thống, monitoring để đảm bảo rằng độ chính xác của hệ thống ML không bị giảm theo thời gian.
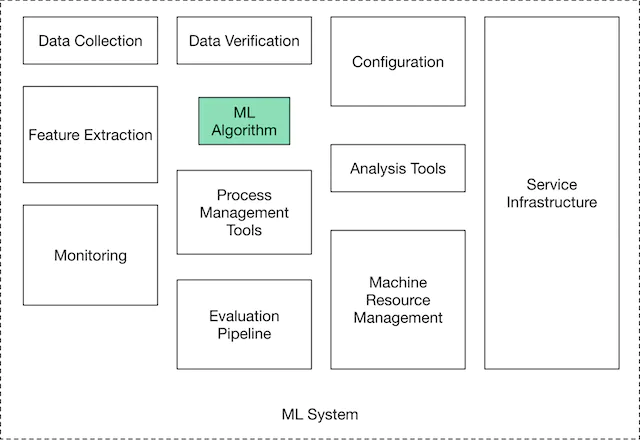
Để xây dựng một hệ thống ML cần trả lời một loại câu hỏi đã được thiết kế sẵn. Dưới đây là các thành phần mà tôi đề xuất và sẽ được dùng xuyên suốt loạt bài viết này:
- Làm rõ yêu cầu
- Đặt vấn đề thành một bài toán ML
- Chuẩn bị dữ liệu
- Phát triển mô hình ML
- Đánh giá mô hình
- Triển khai
- Monitoring
Làm rõ yêu cầu
Chúng ta cần làm rõ các yêu cầu khi thiết kế một hệ thống ML. Dưới đây là danh sách các câu hỏi cần được làm rõ:
- Mục tiêu kinh doanh: Nếu chúng ta được yêu cầu thiết kế một hệ thống đề xuất các nhà nghỉ du lịch, thì chúng ta thường sẽ có 2 mục tiêu là tăng số lượng booking và tăng doanh thu
- Các tính năng của hệ thống: Hệ thống cần có những chức năng gì mà có thể ảnh hưởng đến thiết kế của hệ thống ML. Ví dụ, với một hệ thống đề xuất video, chúng ta có thể cần biết răng người dùng có thể ấn like hoặc dislike các video được đề xuất ko, vì các tương tác này có thể được dùng để gán nhãn cho dữ liệu huấn luyện
- Dữ liệu: Nguồn dữ liệu là gì? Lớn đến mức nào và đã được gán nhãn chưa?
- Constraints: Năng lực tính toán như thế nào? Đây có phải là hệ thống trên cloud hay hệ thống có thể hoạt động trên thiết bị? Mô hình có phải cần cải thiện tự động theo thời gian không?
- Scale: chúng ta có bao nhiêu user? Có bao nhiêu đối tượng, ví dụ như video, mà chúng ta sẽ phải làm việc? Mức độ tăng trưởng của các số liệu này như thế nào?
- Hiệu năng: một dự đoán cần thực hiện trong tối đa bao lâu? Có cần phải là giải pháp theo thời gian thực không? ưu tiên độ chính xác hay là độ trễ?
Danh sách này chưa phải hoàn hảo nhưng có thể dùng nó để làm một điểm bắt đầu. Các chủ đề khác như an toàn dữ liệu cũng nên được cân nhắc.
Đặt vấn đề thành một bài toán ML
Trong thực tế, ban đầu chúng ta cần quyết định rằng phương pháp ML có cần để giải quyết vấn đề không. Đối với một bài toán ML, chúng ta có thể coi vấn đề thành một bài toán ML theo các bước:
- Định nghĩa mục tiêu của bài toán
- Xác định đầu vào, đầu ra của hệ thống
- Xác định thuộc dạng bài toán ML nào
Định nghĩa mục tiêu bài toán
Mục tiêu của kinh doanh có thể là tăng doanh số thêm 20%, nhưng mà chúng ta không thể huấn luyện một mô hình bằng cách nói với nó rằng “tăng doanh số thêm 20%” :) . Để giải quyết bài toán, chúng ta cần chuyển mục tiêu kinh doanh sang bài toán ML một cách rõ ràng. Ví dụ:
| Application | Business objective | ML objective |
|---|---|---|
| Ứng dụng bán vé sự kiện | tăng doanh số bán vé | Tối đa số lượng đăng ký dự sự kiện |
| Ứng dụng video streaming | tăng tương tác người dùng | Tối đa thời gian xem của người dùng |
| Hệ thống dự đoán click vào quảng cáo | Tăng số lượng click | Tối đa tỉ lệ click-through |
| Phát hiện nội dung độc hại trong một nền tảng media | Cải thiện tính an toàn của nền tảng | Dự đoán nội dung có phải là độc hại |
| Đề xuất kết bạn | Tăng tỉ lệ người dùng gia tăng network của họ | Tối đa số lượng kết bạn |
Xác định đầu vào, đầu ra của hệ thống
Khi ta đã xác định được ML objective, chúng ta cần định nghĩa input và output của hệ thống. Ví dụ, một hệ thống phát hiện nội dung độc hại trên một nền tảng mạng xã hội, đầu vào là một post, đầu ra là post đó có phải là độc hại không.
Trong một vài trường hợp, hệ thống có thể bao gồm nhiều mô hình ML. Khi đó, chúng ta cần xác định đầu vào và đầu ra cho mỗi mô hình. Ví dụ trong hệ thống phát hiện nội dung độc hại, chúng ta có thể sử dụng một mô hình để phát hiện bạo lực và một mô hình khác để phát hiện ảnh 18+.
Một cân nhắc quan trọng nữa đó là có thể có nhiều cách để xác định đầu vào và đầu ra cho mô hình. Ví dụ:
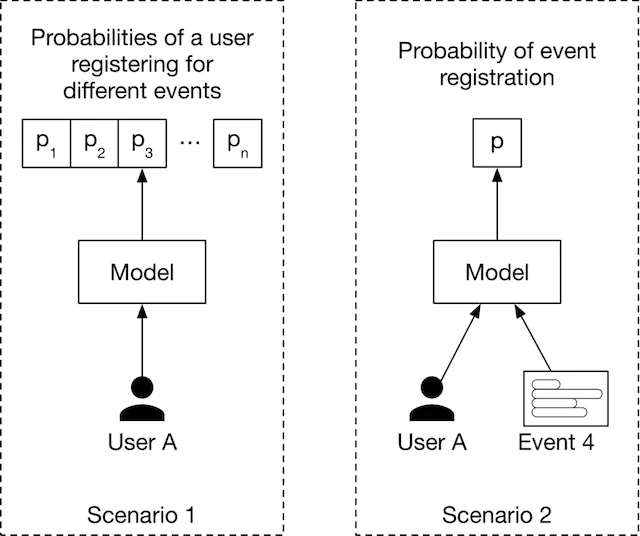
Xác định thuộc dạng bài toán ML nào
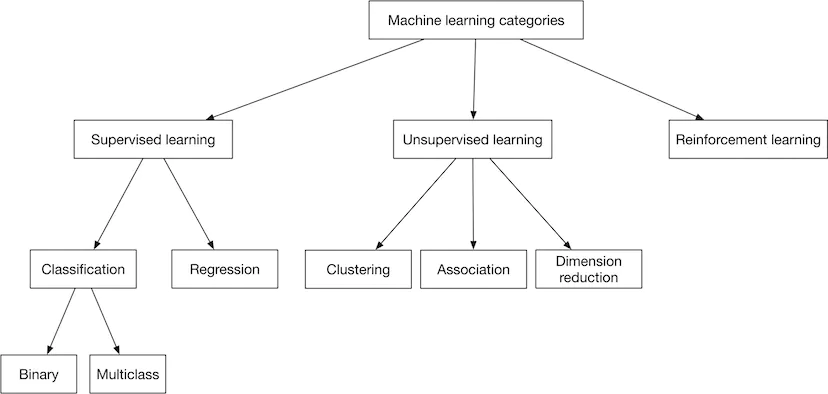
Các dạng bài toán ML quen thuộc như hình dưới đây:
Dữ liệu
Có 2 công đoạn quan trọng để chuẩn bị dữ liệu tốt cho mô hình ML đó là data engineering và feature engineering như hình dưới:

Data engineering
Data engineering là công việc thiết kế và xây dựng pipelines cho việc collecting, storing, retrieving và processing data. Dưới đây tôi sẽ giới thiệu qua về các thành phần chủ yếu này.
-
Data sources Dữ liệu ở một hệ thống ML có thể đến từ nhiều nguồn khác nhau. Biết được nguồn data có thể trả lời được nhiều câu hỏi như ai là người thu thập, data có sạch không, nguồn data có đáng tin cậy không, data được tạo từ người dùng hay là từ hệ thống,..
-
Data storage Hay còn gọi là database, là một nơi để lưu trữ và quản lý data. Các trường hợp sử dụng khác nhau sẽ cần đến kiến trúc database khác nhau nên cần phải hiểu rõ các database hoạt động như thế nào.

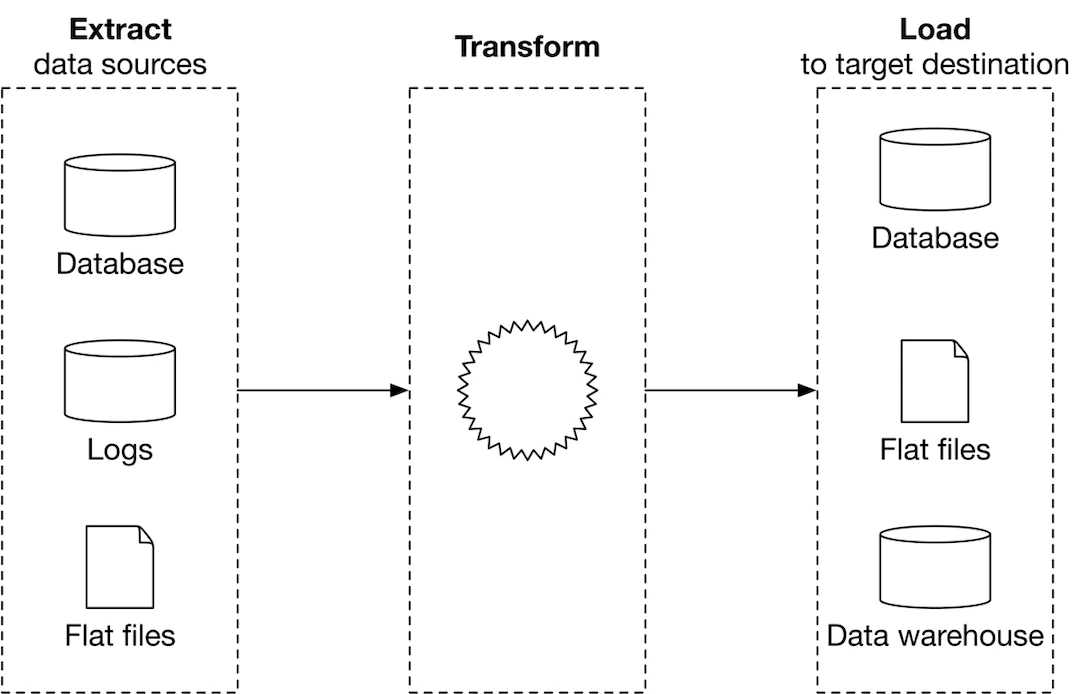
- Extract, transform, and load (ETL)
ETL bao gồm :
- Extract lấy data từ nhiều nguồn khác nhau
- Transform làm sạch và biến đổi data thành một format nào đó phù hợp với nhu cầu sử dụng.
- Load dữ liệu đã được transform sẽ được tải lên nơi để lưu trữ như là database hay data warehouse.
- Data types
Trong ML, kiểu dữ liệu khác so với trong các ngôn ngữ lập trình, như int, float, string,.. Kiểu dữ liệu có thể được chia thành: structured và unstructured.
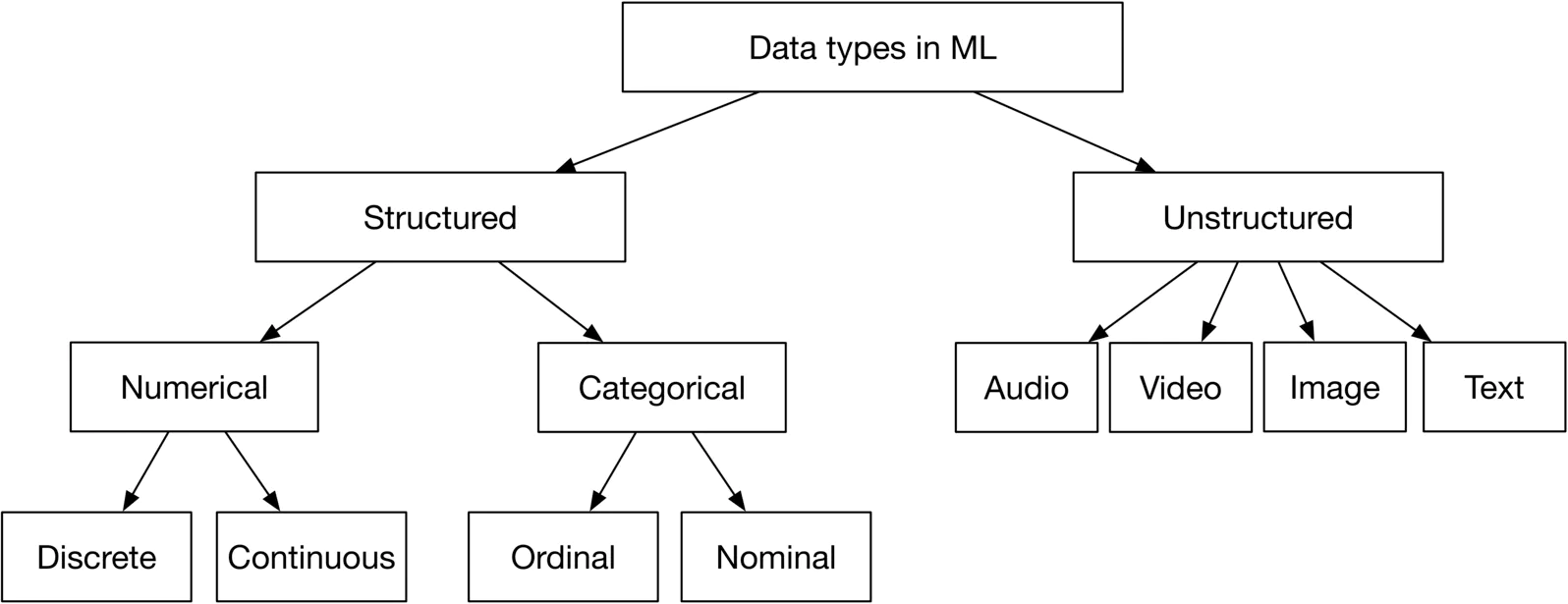
Dưới đây là các điểm khác biệt chủ yếu giữa structured data và unstructured data
| Structured data | Unstructured data | |
|---|---|---|
| Characteristics | Predefined schema Easy to search |
No schema Difficult to search |
| Resides in | Relational databases Many NoSQL databases can store structured data Data warehouses |
NoSQL databases Data lakes |
| Examples | Dates Phone numbers Credit card numbers Addresses Names |
Text files Audio files Images Videos |
Hiểu rõ data là structured hay unstructred có thể giúp chúng ta chọn được mô hình ML phù hợp.
- Numerical data
Numerical data là các điểm data dưới dạng các số, được chia thành kiểu rời rạc và liên tục. Ví dụ, giá nhà có thể được xem là giá trị liên tục vì giá nhà có thể lấy bất kỳ giá trị nào trong một khoảng. Ngược lại, số lượng nhà bán ra được trong một năm trước thì là giá trị rời rạc, vì nó chỉ có thể có một số giá trị nhất định.
- Categorical data Categorical data là loại data có thể được lưu trữ dựa vào tên gọi hoặc nhãn của chúng. Ví dụ, giới tính là categorical data vì giá trị của nó chỉ có một vài nhãn. Categorical data có thể chia thành 2 loại là nominal và ordinal.
Nominal data là kiểu data mà không có bất kỳ mối quan hệ nào giữa các nhãn của chúng. Ví dụ giới tính nam và nữ là nominal data. Ordinal data là kiểu data có thứ tự định nghĩa trước. Ví dụ các cảm xúc “not happy”, “neutral”, “happy” là một kiểu ordinal data.
Feature Engineering
Feature engineering gồm 2 quá trình:
- Sử dụng domain knowledge để lựa chọn và trích xuất feature từ raw data
- Biến đổi features thành format có thể được sử dụng bởi mô hình
Lựa chọn đặc trưng phù hợp là một trong những quyết định quan trọng khi phát triển một mô hình ML. Feature được chọn cần phải có nhiều giá trị nhất và sẽ có một hiểu biết nhất định về lĩnh vực đang làm. Khi đặc trưng đã được chọn, chúng cần được biến đổi thành các định dạng phù hợp sử dụng feature engineering operations.
Feature Engineering operations
Quá trình này sẽ biến đổi đặc trưng thành các định dạng mà mô hình có thể sử dụng được. Bao gồm công việc xử lý missing values, scaling values, encoding categorical features. Dưới đây là một vài operation thường gặp cho structured data:
- Handling missing values
Data thường sẽ có các giá trị bị mất, ta có thể xử lý bằng 2 phương pháp là deletion hoặc imputation:
- Deletion phương pháp xóa các record mà có giá trị bị thiếu. Phương pháp này chia làm 2 loại là xóa cột và xóa dòng. Khi xóa cột, chúng ta xóa toàn bộ cột mà có đặc trưng bị thiếu quá nhiều. Khi xóa dòng, chúng ta sẽ xóa các điểm dữ liệu mà có nhiều giá trị bị mất. Nhược điểm của phương pháp deletion là nó sẽ giảm số lượng data mà mô hình có thể dùng để học và mô hình có thể làm tốt hơn nếu nó được thấy nhiều dữ liệu hơn. Dưới đây là ví dụ về xóa cột

- Imputation Thay vào đó, chúng ta có thể thay thế giá trị bị mất với một giá trị nhất định nào đó:
- Thay bằng giá trị mặc định
- Thay bằng giá trị trung bình, hoặc giá trị xuất hiện nhiều nhất
Nhược điểm của phương pháp này là nó có thể tạo ra dữ liệu nhiễu. Sẽ không có phương pháp nào là hoàn hảo, mỗi chúng đều có trade-offs.
- Feature scaling
Đây là quá trình scaling features về phân phối chuẩn. Nhiều mô hình ML sẽ cho kết quả không tốt nếu feature của data nằm ở nhiều khoảng giá trị khác nhau. Dưới đây là một vài kỹ thuật scaling.
- Normalization (min-max scaling). Phương pháp này sẽ scale feature về khoảng [0, 1] sử dụng công thức: $z = \frac{x-xmin}{xmax-xmin}$ Normalization vẫn sẽ giữ nguyên phân phối của feature. Để thay đổi phân phối feature về phân phối chuẩn, ta có thể dùng standardization
- Standardization (Z-score normalization). Đây là quá trình chuẩn hóa đặc trưng về phân phối chuẩn với trung bình bằng 0 và độ lệch chuẩn bằng 1. Công thức: $z = \frac{x-\mu}{\sigma}$ Với $\mu$ là trung bình và $\sigma$ là độ lệch chuẩn của feature.
-
Discretization (Bucketing) Đây là quá trình chuyển đổi đặc trưng kiểu liên tục thành đặc trưng kiểu rời rạc. Ví dụ, để thể hiện chiều cao, chúng ta có thể chia chiều cao thành các khoảng giá trị, điều này sẽ giúp cho mô hình tập trung học một vài loại nhãn.
- Encoding categorical features Đối với các mô hình ML, tất cả các input và output đề phải là kiểu số. Điều này có nghĩa là ta phải encode các đặc trưng thành các số trước khi đưa vào mô hình. Có 3 cách thường được sử dụng để chuyển đặc trưng về dạng số: inter encoding, one-hot encoding, embedding learning.
Ở bài tiếp theo, tôi sẽ nói tiếp về quá trình phát triển mô hình và các công đoạn sau đó trong một quá trình xây dựng hệ thống ML.