Model Development
Các bước tiếp theo trong quá trình phát triển một hệ thống ML dó là deployment-serving và monitoring.
Deployment and Serving
Đây là quá trình đưa mô hình lên production và serve đến người dùng. Các topic quan trọng bao gồm:
- Cloud vs on-device deployment
- Model compression
- Testing in production
- Prediction pipeline
Cloud vs on-device deplotment
Dưới đây là các điểm khác nhau giữa deploy mô hình lên device và lên cloud
| Cloud | On-device | |
|---|---|---|
| Simplicity | Simple to deploy and manage using cloud-based services | Deploying models on a device is not straightforward |
| Cost | Cloud costs might be high | No cloud cost when computations are performed on-device |
| Network latency | Network latency is present | No network latency |
| Inference latency | Usually faster inference due to more powerful machines | ML models run slower |
| Hardware constraints | Fewer constraints | More constraints, such as limited memory, battery consumption, etc. |
| Privacy | Less privacy as user data is transferred to the cloud | More privacy since data never leaves the device |
| Dependency on internet connection | Internet connection needed to send and receive data to the cloud | No internet connection needed |
Model compression
Nén model là quá trình làm cho model nhỏ hơn, giúp cho giảm inference latency và kích cỡ model. Có 3 phương pháp thường được sử dụng đó là:
- Knowledge distillation mục tiêu là huấn luyện một mô hình nhỏ có thể “bắt chước” được một mô hình lớn hơn
- Pruning là quá trình bỏ đi các trọng số không cần thiết (đưa về 0)
- Quantization các trọng số của mô hình thường sẽ ở kiểu 32-bit float. Với quantization, chúng ta sẽ sử dụng ít bit hơn để thể hiện các trọng số, giúp mô hình nhỏ hơn và tính toán nhanh hơn.
Test in production
Cách duy nhất để chắc chắn model hoạt động tốt ở production là test nó với real traffic. Có vài phương pháp hay được sử dụng đó là shadow deployment, A/B testing, canary release, interleaving experiments, bandits, etc. Chúng ta sẽ đi vào 2 phương pháp là shadow deployment và A/B testing
- Shadow deployment Với phương pháp này, chúng ta sẽ deplot model mới song song với model hiện tại. Mỗi request sẽ được đưa đến cả 2 model nhưng chỉ có kết quả của model hiện tại mới được trả về cho user. Với cách làm này, chúng ta sẽ giảm thiểu rủi to khi deploy một mô hình mới. Nhưng nhược điểm của cách làm này sẽ tăng số lượng predictions lên gấp đôi.
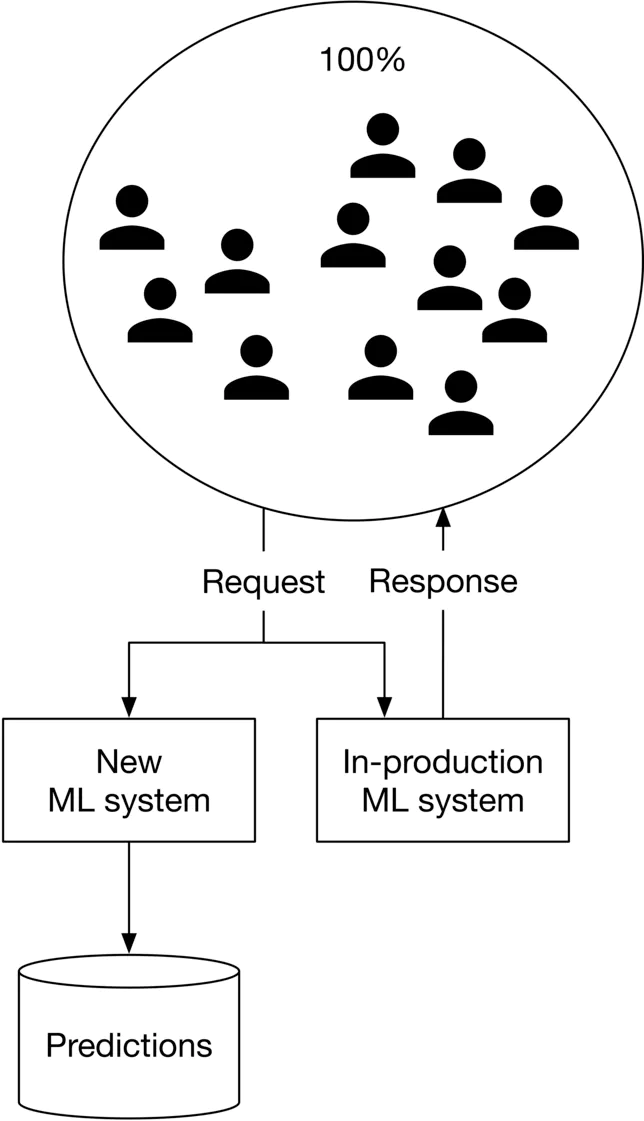
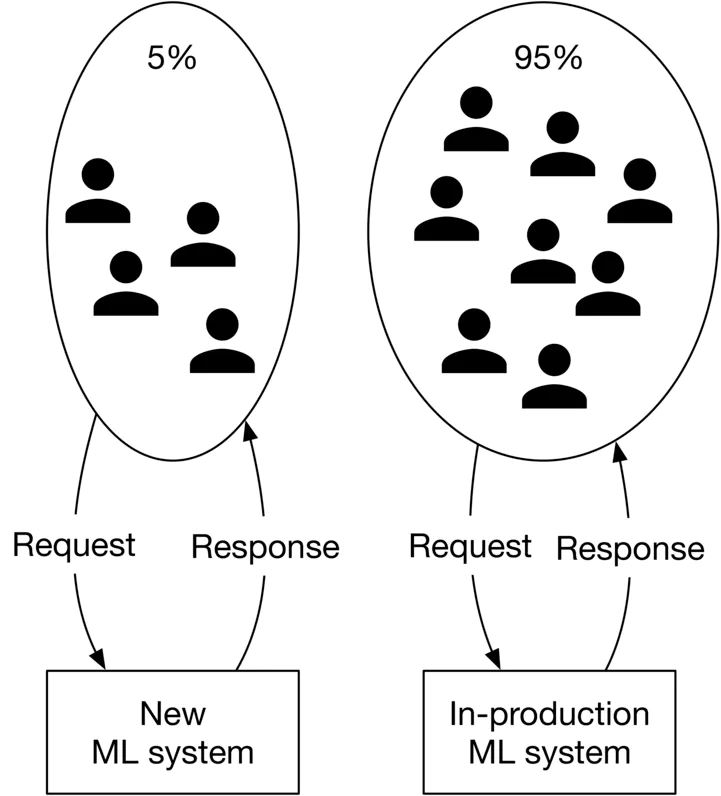
- A/B testing
Ở phương pháp này, chúng ta cũng deploy model mới lên song song với model hiện tại, nhưng chỉ một phần của request được gửi đến model mới này. Các request gửi đến model mới phải là ngẫu nhiên và số lượng request phải đủ nhiều để thu được kết quả test đúng với thực tế.
Prediction pipeline
Để serve request ở trên production, chúng ta cần một prediction pipeline. Có 2 kiểu thiết kế đó là online prediction và batch prediction
- Batch prediction Với batch prediction, mô hình sẽ thực hiện dự đoán theo định kỳ. Các dự đoán sẽ được thực hiện từ trước và khi có request đến, chỉ cần search lại kết quả. Đối với phương pháp này, chúng ta sẽ không cần quan tâm đến tốc độ làm việc của mô hình. Tuy nhiên, batch prediction có 2 nhược điểm lớn. Thứ nhất đó là các đặc trưng bị lỗi thời hoặc các dự đoán bị lỗi thời (ie người dùng thay đổi sở thích). Thứ hai, phương pháp này chỉ được áp dụng cho các bài toán mà chúng ta đã biết trước điều gì cần được tính toán trước.
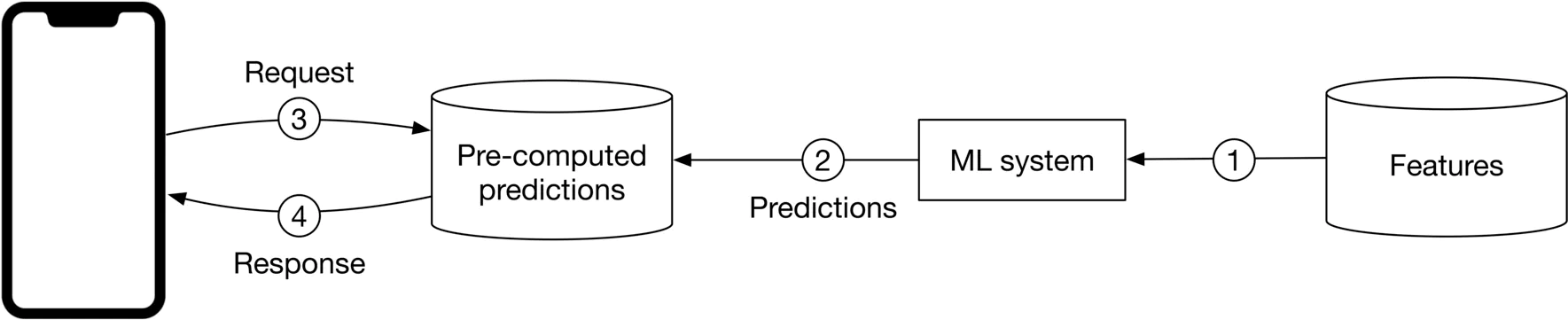
- Online prediction với cách làm này, dự đoán sẽ được thực hiện ngay khi có request đến. Vấn đề chủ yếu của phương pháp này đó là model có thể mất nhiều thời gian để thực hiện tính toán.
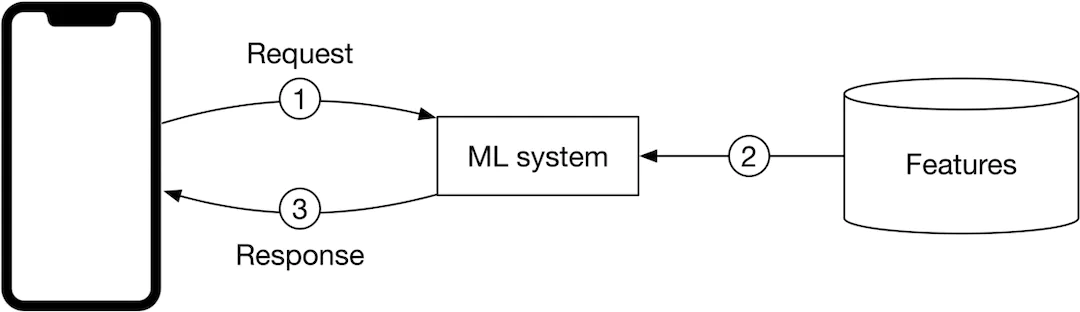
Lựa chọn giữa batch prediction hay online prediction chủ yếu dựa vào yêu cầu của sản phẩm. Online prediction thường được ưu tiên trong các trường hợp mà chúng ta không tính trước được. Batch prediction sử dụng khi hệ thống xử lý một lượng data lớn và không cần real-time
Như đã nói trước đây, hệ thống ML cần nhiều hơn là model. Dưới đây là ví dụ về một hệ thống ML thiết kế cho hệ thống cá nhân hóa new feeds.
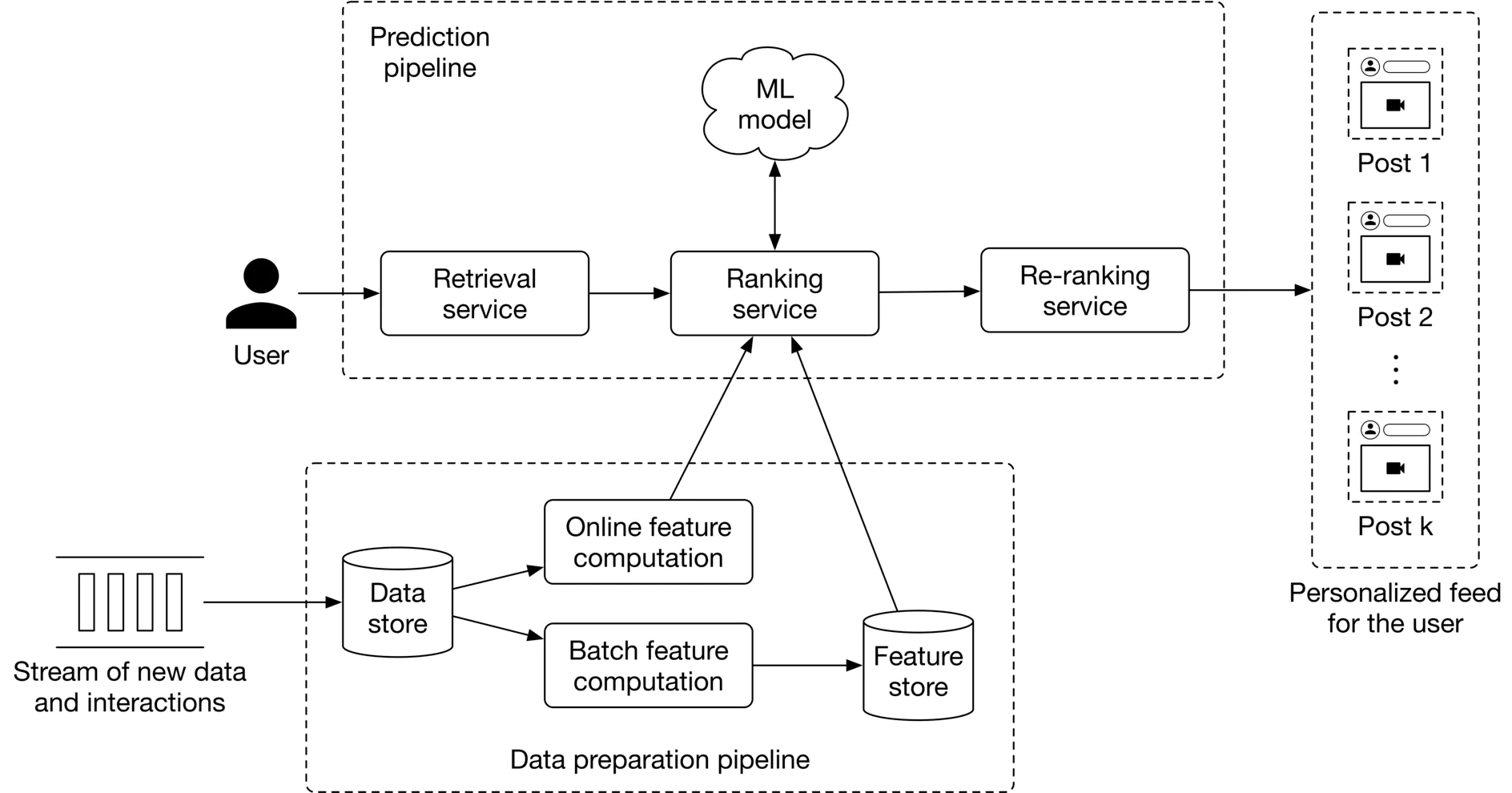
Monitoring
Quá trình theo dõi, đo lường, và logging các metrics khi mô hình hoạt động trên production. Một hệ thống ML có thể fail vì nhiều nguyên nhân. Monitoring giúp phát hiện lỗi hệ thống nhanh chóng để khắc phục kịp thời.
Tại sao một hệ thống fail trên production
Có rất nhiều lý do để một hệ thống ML fail trên môi trường production. Một trong những nguyên nhân phổ biến là data distribution shift. Đây là trường hợp xảy ra khi data mô hình xử lý trên production khác biệt so với lúc training. Do đó, chúng ta phải liên tục monitor hệ thống để phát hiện vấn đề nhanh chóng. 2 phương pháp khắc phục data distribution shift đó là:
- Train trên tập dữ liệu lớn: một tập data đủ lớn cho phép model học được một phân phối data rộng hơn, giúp nó ổn định hơn khi deploy.
- Retrain mô hình định kỳ sử dụng data mới.
What to monitor
Mục tiêu của chúng ta là phát hiện ra được các failure và data shifts trong một hệ thống ML. Chúng ta có thể phân loại các phương pháp monitoring thành 2 loại đó là operation-related và ML-specific metrics.
- Operation-related metrics Các metric đảm bảo rằng hệ thống làm việc ổn định, bao gồm thời gian serving trung bình, throughput, số lượng prediction, CPU/GPU utilization, etc.
- ML-specific metric:
- Monitoring inputs/outputs
- Drifts. Inputs của hệ thống và output của model cần được monitor để phát hiện thay đổi phân phối của chúng.
- Model accuracy.
- Model vesion. (version nào đang được deploy?)
Infrastructure
Infrastructure là nền tảng cho training, deploying và maintaining hệ thống ML. Đây là phần liên quan đến MLOps.
Tổng kết
Trong 3 phần của bài viết này, tôi đã nói về rất nhiều khía cạnh trong việc phát triển một hệ thống ML. Sau này sẽ tiếp tục có những bài viết về việc phát triển hệ thống cho các bài toán ML cụ thể