Các sản phẩm dựa trên các mô hình ngôn ngữ lớn (large language models LLMs) như OpenAi, ChatGPT có những ứng dụng tuyệt vời, tuy nhiên chúng vẫn còn những hạn chế:
- Chúng không thể cập nhật thông tin: các LLMs chỉ có những kiến thức đên một thời điểm nhất định lúc dữ liệu huấn luyện được thu thập.
- Chúng không có các kiến thức cụ thể: LLMs được huấn luyện cho các nhiệm vụ chung.
- Chúng được xem là “black boxes”: không dễ để biết được LLM sử dụng nguồn tài liệu ở đâu và cách chúng đưa ra quyết định dựa trên cơ sở nào.
- Chúng không hiệu quả và đắt tiền: chỉ một ít công ty có đủ tài chính và nguồn nhân lực để triển khai các models nền tảng.
Bài viết này sẽ phân tích tại sao Retrieval Augmented Generation được ưu tiên sử dụng đối phó với những hạn chế kể trên, tìm hiểu sâu về cách RAG làm việt.
LLMs không thể cập nhật thông tin, nhưng RAG thì có thể
Dữ liệu để huấn luyện ChatGPT chỉ đến tháng 9 năm 2021. Nếu bạn hỏi ChatGPT một vấn đề xảy ra vào tháng trước, nó sẽ không thể đưa ra câu trả lời chính xác và nó sẽ tưởng tượng ra một câu trả lời hết sức thuyết phục, hiện tượng này còn được gọi là “hallucination”.
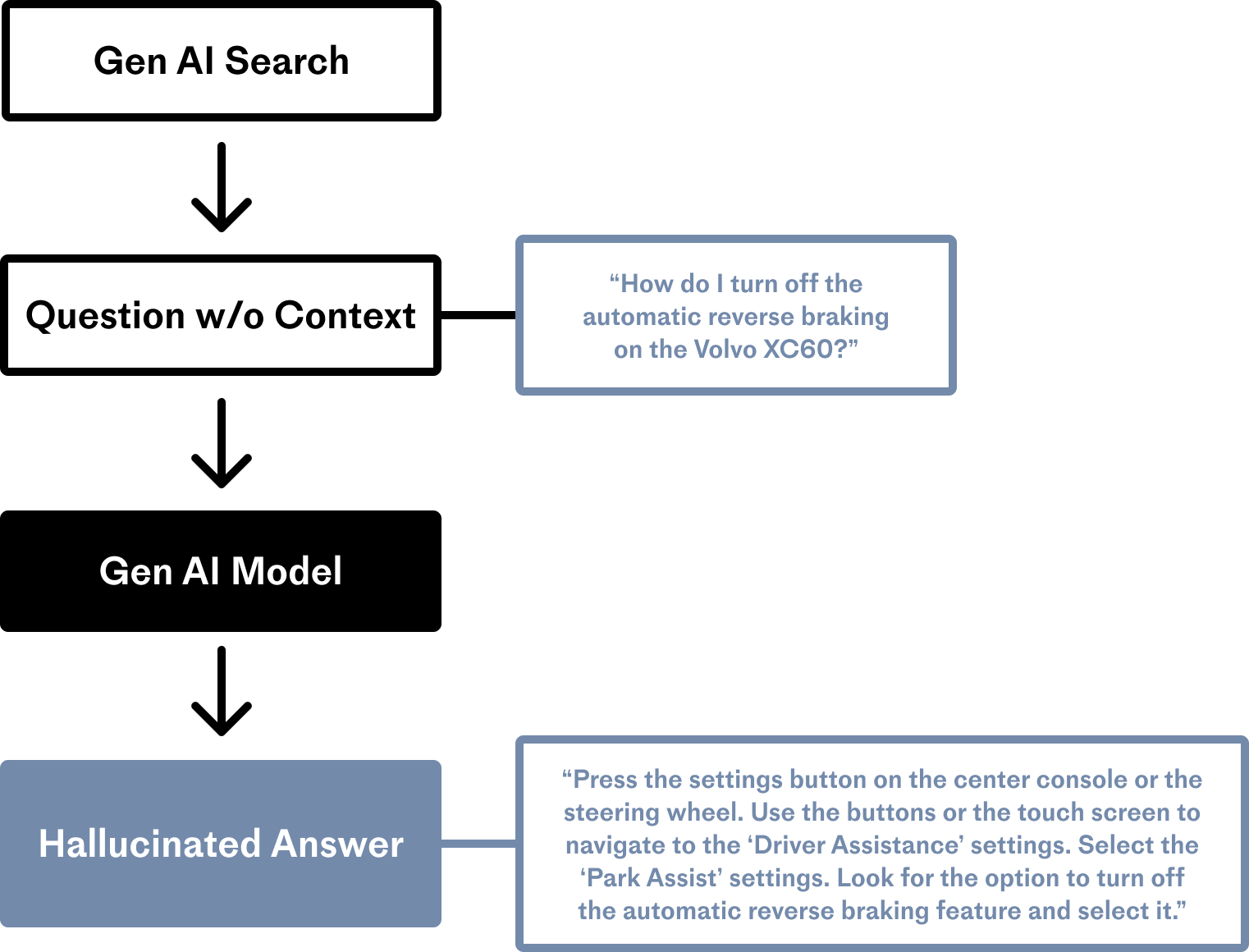
LLMs thiết thông tin cụ thể về Volvo XC60 trong ví dụ trên và nó cố gắng trả lời trông có vẻ rất đúng nhưng các thông tin đều không chính xác.
RAG cung cấp các thông tin cập nhật về thế giới và các dữ liệu mang tính cụ thể cho các ứng dụng GenAI
Retrieval Augmented Generation có nghĩa là lấy các thông tin cập nhật hoặc các dữ liệu từ database và biến chúng trở thành kiến thức của LLM. Chúng ta có thể lưu các dữ liệu về kinh doanh hoặc thông tin về thế giới và để cho LLM “biết” về nó trong lúc nó trả lời câu hỏi, điều này giúp làm giảm hiện tượng hallucinations.
LLMs thiếu các nội dung từ dữ liệu riêng tư - dẫn đến hallucinations khi được hỏi các câu hỏi có tính cụ thể như về thông tin riêng tư của công ty
Nhược điểm thứ 2 của LLMs là mặc dù các kiến thức nền của chúng là khổng lồ, thì chúng vẫn không có thông tin về các yêu cầu của bạn, khách hàng của bạn, hoặc về cửa hàng của bạn.
RAG giúp giải quyết vấn đề này bằng cách thêm vào các ngữ cảnh và thông tin đến LLMs lúc nó đưa ra câu trả lời: có thể là bản ghi của khách hàng, kịch bản, mô tả sản phẩm, giá chứng khoán,..
Retrieval Augmented Generation cho phép GenAI có thể trích nguồn và cải thiện kết quả
RAG cho phép các ứng dụng GenAI trích dẫn nguồn giống như các bài báo khoa học. Điều này sẽ giúp việc kiểm tra và hiểu dễ dàng hơn cách các ứng dụng GenAi hoạt động.
Tại sao RAG được sử dụng nhiều
Ngoài ra RAG thì có 3 lựa chọn để cải thiện ứng dụng GenAI. Chúng ta sẽ tìm hiểu về chúng để hiểu được tại sao RAG lại được ưa thích hơn cả.
Tự xây dựng model nền tảng
OpenAI ước tính rằng tốn khoảng 100 triệu đô cho mô hình ChatGPT. Không phải tất cả các model đều cần số tiền lớn như vậy, nhưng điều này cũng cho thấy rằng, chi phí là một thử thách lớn trong việc tạo ra một mô hình phức tạp có thể hoạt động đủ tốt.
Bên cạnh vấn đề chi phí đó là vấn đề về con người - bạn cần một team toàn những “siêu sao” về machine learning, system engineer, devops, để có thể đối đầu với hàng loạt vấn đề có thể gặp phải trong lúc xây dựng model.
Một vấn đề khác nữa là bạn sẽ cần các chuyên gia để đánh nhãn trong các lĩnh vực khó đòi hỏi kiến thức chuyên sâu. Ví dụ như một công ty luật cần một model có thể trả lời các kiến thức về luật pháp, thì bạn sẽ cần nhiều chuyên gia về luật giành nhiều thời gian để đánh nhãn cho model.
Và cuối cùng, giả sử bạn đã có đủ tiền và con người rồi, thì cũng chưa chắc đã thành công. Đã có nhiều AI startup nổi lên rồi lại lụi tàn, và chắc chắn sẽ còn nhiều thất bại nữa.
Fine-tuning: huấn luyện model nền tảng để hiểu về dữ liệu chuyên biệt của bạn.
Fine-tuning là quá trình huấn luyện lại model nền tảng trên dữ liệu mới. Điều này tiết kiệm chi phí hơn nhiều so với xây dụng mô hình từ đầu. Dù vậy, hướng tiếp cận này cũng có những thách thức: bạn cần dữ liệu đủ và có tính chuyên môn sâu, và chi phí và kỹ thuật để vận hành model sẽ là những thử thách lớn.
Fine-tuning không còn là một hướng tiếp cận thực tế nữa. Nó tốn kém trong việc đánh nhãn và quản lý phân phối dữ liệu. Nếu dữ liệu thay đổi theo thời gian, thì chắc chắn rằng độ chính xác của model sẽ giảm và lúc đó chúng ta lại cần đánh nhãn lại và fine-tune, điều này sẽ rất mất thời gian.
Prompt engineering là không đủ để giảm hallucinations
Prompt engineering là cung cấp hướng dẫn cho model để nó có thể làm theo điều bạn muốn. Đây là hướng tiếp cận ít tốn chi phí nhất vì nó chỉ cần một vài dòng code để thực hiện việc hướng dẫn LLM trả lời.
Nhưng phương pháp này không thể cung cấp các ngữ cảnh hiện tại cho LLMs và vẫn sẽ gặp vấn đề hallucination.
Retrieval Augmented Generation hoạt động như thế nào
Chúng ta sẽ tìm hiểu về cách RAG đưa các thông tin liên quan từ database đến cho LLM lúc nó tạo câu trả lời, dựa vào câu prompt gốc, thông qua một “context window”.
Context widown có thể xem là “tầm nhìn” của LLM trong một chốc lát. RAG nắm giữ các thông tin quan trọng để LLM thấy được, giúp nó tạo ra các phản hồi chính xác hơn nhờ vào việc kết hợp với các thông tin quan trọng.
Để hiểu RAG, trước tiên chúng ta phải hiểu semantic search, là quá trình tìm kiếm ý nghĩa của query và lấy ra thông tin liên quan. Semantic search cố gắng đưa ra các kết quả gần với mong muốn của user nhất.
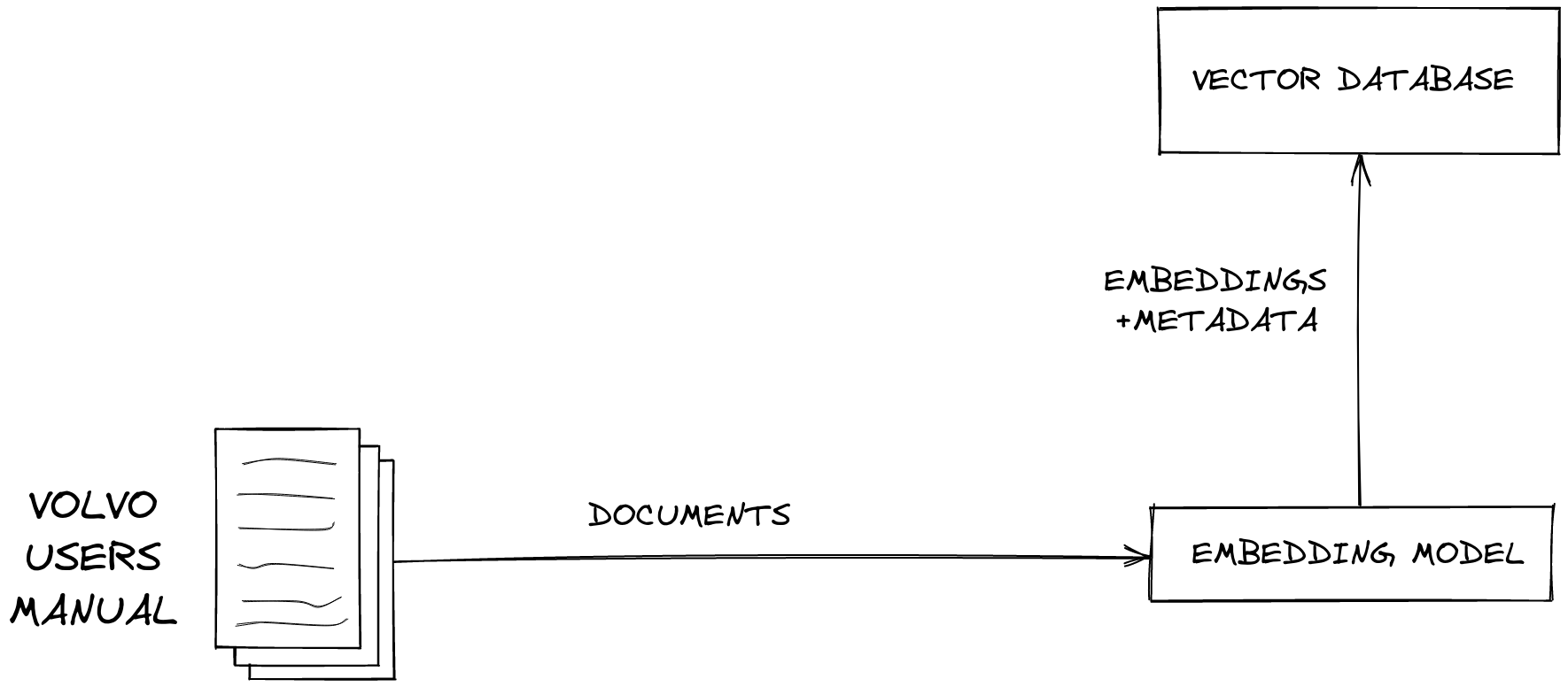
Biểu đồ này mô tả cách tạo một vector database bằng cách biến đổi dữ liệu đầu vào thành vector thông qua một embedding model.
Một embedding model là một dạng LLM có thể chuyển dữ liệu thành vector. Dữ liệu có thể là ảnh, văn bản hoặc âm thanh, video.
Tiếp đó, ta sẽ đưa vector vào trong vector database, vector database sẽ hỗ trợ việc tìm kiếm các vector tương đồng nhanh nhất khi thực hiện semantic search.
Semantic search: biến đổi query thành embeddings và sử dụng vector database để tìm kiếm tương tự
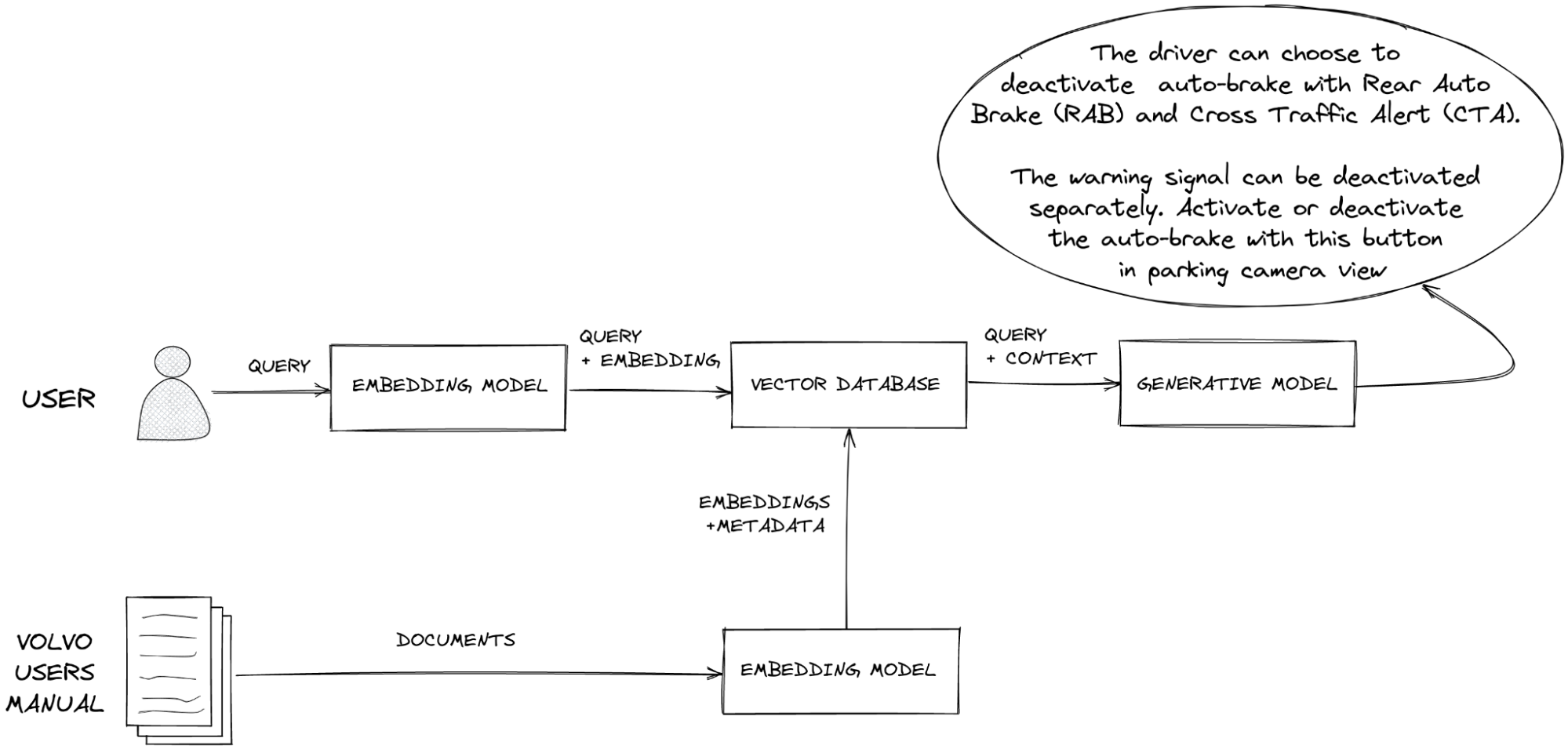
Khi người dùng đưa vào câu query, ta sẽ chuyển nó thành embeddings. Sau đó, ta sẽ thực hiện việc tìm kiếm tương đồng trong vector database. Khi vector database trả về các kết quả tìm kiếm được, ứng dụng sẽ cung cấp nó cho LLM thông qua cơ chế context window, và thực hiện prompting để tạo ra câu phản hồi.
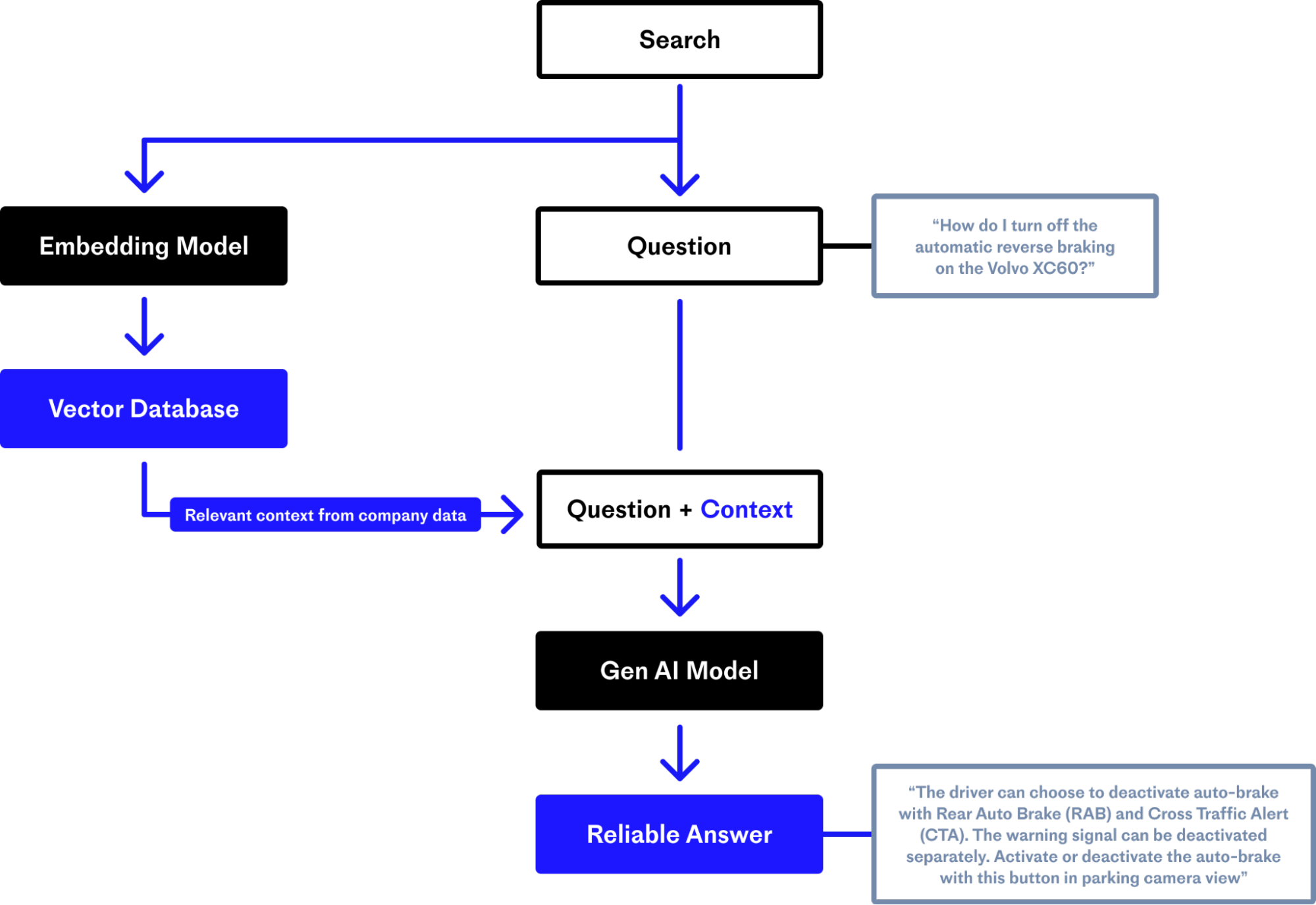
Như vậy, LLM đã có thể tiếp cận với các thông tin liên quan từ vector database, nó có thể cung cấp câu trả lời chính xác cho người dùng. RAG đã làm giảm đi hiện tượng hallucination.
Tổng kết
RAG là một hướng tiếp cận hiệu quả nhất, dễ dàng thực hiện và ít rủi ro nhất để có thể nâng cao performance của các ứng dụng GenAI.